Tutorial 10 - Docker Containers¶

![]()
Introduction¶
Ensuring the reproducibility of Data Science projects is important for several reasons. One is that our customers (internal within your organization, or external) may use different operating systems, code dependencies, hardware, and they should be able to use our developed product and obtain the expected results. Another reason is collaborative development, where we may need to share our code with collaborators, and ensuring reproducibility of our code requires information about the full environment in which the code was developed.
Predictions of Machine Learning models depend on the model architecture and parameters, code, libraries and dependencies needed to run the code. Ensuring reproducibility is a challenge that can affect the performance if not addressed. Regarding the model architecture and weights, we can simply save and load them, to ensure that the same model is used and that the predictions are consistent. Regarding code, we can use fixed random seeds and version control to ensure that the same data and code are used for training the model and making predictions. Dealing with code libraries and dependencies is more challenging, because libraries are updated frequently, and the model behavior can change, or even worse, the code can crash with some updates. To address this issue requires to apply a strategy for constraining the environment in which the model is developed and deployed.
The main strategies to constrain the libraries and dependencies include:
Interoperable standards,
Virtual environments,
Docker containers.
The first strategy involves standards like Open Neural Network Exchange (ONNX). ONNX is an open-source format for representing neural networks that allows interoperability between different frameworks (such as PyTorch and TensorFlow), or between different platforms. E.g., it allows a model trained in PyTorch to be imported and used for predictions in TensorFlow. Despite the potential, this strategy requires to frequently update the tools as the frameworks are updated, it has limited support for some operations in neural networks, it often has bugs in the conversions between the frameworks, and the performance of models can differ after the conversion to a target framework.
The second strategy is to use virtual environments in Python or Conda. Although using virtual environments can isolate Python-level dependencies, they provide only partial solution, since operating system-level dependencies or dependencies like CUDA that involve interaction with hardware may be outside the scope of virtual environments and cannot be addressed with this strategy. The differences in OS-level dependencies or CUDA can impact execution consistency.
The third strategy relies on using Docker containers and it is widely adopted at present time. Docker is an open-source library that uses containers to constrain project dependencies. Container is a standardized unit of fully packaged software used for local development, shipping code, and deploying systems.
Docker¶
An example of the reproducibility challenge with Data Science projects is shown in the next figure, depicting the multiple points for failure when we move our code to a cluster. These issues can include different versions of libraries, dependencies, drivers, or operating system. The main advantages of Docker containers are that they contain all dependencies, including hardware libraries, and ensure reproducible and consistent code performance.
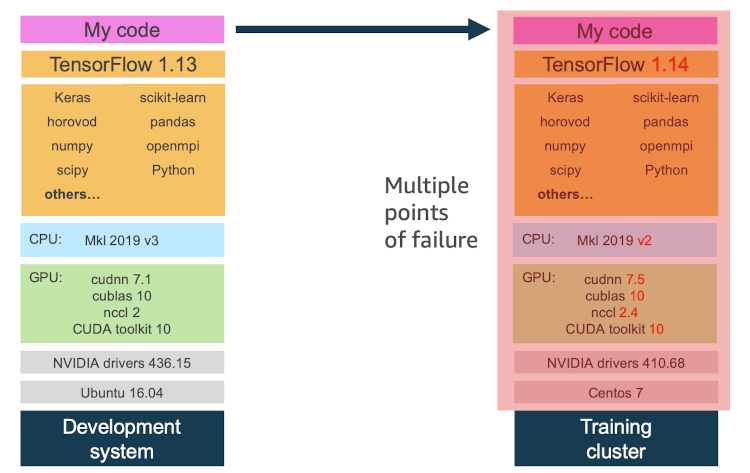
Figure: Reproducibility challenge.
Characteristics of containers are:
Portable: because containers encapsulate the application code, dependencies, and runtime environment, making them independent of the specific setup of the host system. Although containers share the host operating system’s kernel, they can be run seamlessly across machines with compatible operating systems and hardware architectures. This portability enables teams to easily collaborate on projects and experiment with new software or frameworks without spending time configuring environments.
Lightweight, since the containers don’t require a full operating system, and they share the kernel of the host operating system.
Scalable, applications can easily be scaled by adding or removing container instances.
Secure, the application and its dependencies run in an isolated environment, hence the containers are less exposed to attacks.
Facilitate deployment, where Data Science projects can be easily containerized and deployed for consumption by the end-users, with consistent performance between development and production environments.
Note also that there are notable differences between containers and Virtual Machines (VMs). VMs run a complete operating system with its own kernel, and each VM operates as an independent instance with its dedicated resources. Containers do not require hypervisor or hardware virtualization, and they share the host’s operating system kernel. This means that containers only need to package the application, its dependencies, and the minimal required components to run, without duplicating the entire operating system. Because of that, containers are smaller in size and faster to boot. VMs offer stronger isolation than containers, because each VM operates independently of the host, whereas containers share the same kernel with the host. Orchestration tools for containers such as Kubernetes and Docker Swarm can be used to manage and scale containerized applications across clusters of machines, whereas orchestration of VMs is more complex. Containers are well-suited for microservices architectures, continuous integration and deployment (CI/CD), and scalable, distributed applications, while VMs are used for running legacy applications, and environments requiring strong isolation or using multiple operating systems.
Important concepts for working with Docker include:
Dockerfile - script that defines the steps to build a Docker image.
Image - is a built package containing the application and its dependencies.
Container - is an instance where the Docker image is run.
We will explain these concepts through several examples in the following sections.
Installing Docker
Using Docker on a Windows machine can be done by the app Docker Desktop for Windows. This requires to download the app and install it. Depending on the Windows operating system, it may also require to install updates for Windows Subsystem for Linux, and other libraries. It is also possible to install Docker from the command line. Please follow the instructions on the Docker page for more detailed information.
Hello World in Docker¶
Let’s start with a simple “Hello World” example in Docker, where the goal is to create a container with a Python file to print the Hello World! statement.
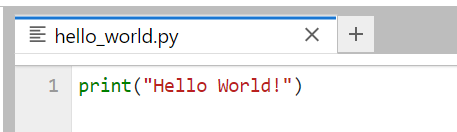
Step 1: Create a Python Script¶
For this purpose, we will create the Python script shown below that has just one line of code, and we will save it under the name hello_world.py in the folder demo1.
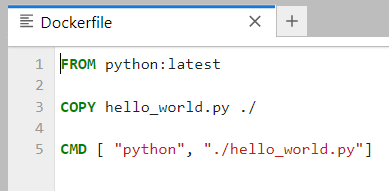
Step 2: Create a Dockerfile¶
Dockerfiles provide instructions for defining custom environments for our projects. I.e., for each particular project we will define the required software packages and libraries in a Dockerfile, and we will use the Dockerfile to build a Docker image.
It is common to start the Dockerfile with a base environment, which can simply include the latest Python version. Alternatively, as a base environment we can import pre-build environments by other developers. Docker provides access to Docker Hub, which is a registry with a large number of Docker images that have been published by other developers, and allows to directly import and take advantage of many pre-built environments.
Dockerfiles are plain text files, and for this simple project the Dockerfile is shown below:
The first line uses the
FROMcommand to instruct Docker to use Python as a base image for the environment. The termlatestinstructs Docker to retrieve the image of the latest official Python version. Docker will first check if we have the latest Python version installed on our machine, and if we don’t, Docker will automatically download the image from Docker Hub. Alternatively, if we wanted to work with an earlier Python version, we can just writeFROM python:3.5orFROM python:2.7, for example.The second line uses the
COPYcommand to copy the createdhello_world.pyfile from the local folder on my computer to the filesystem of the Docker image. The notation./is used for the root directory of the Docker image. The syntax isCOPY source_directory destination_directory.The third line uses the
CMDcommand to execute thehello_world.pyscript from the root directory in the image when the container is run.
The file needs to be saved under the name Dockerfile. The organization of the Demo1 folder is:
Demo1
├── Dockerfile
├── hello_world.py
Step 3: Build the Docker Image¶
Docker image is a template that contains instructions for creating a container that runs on the Docker platform. It provides a convenient way to package up code and preconfigured environments, which we can use for our own private use or share publicly with other Docker users.
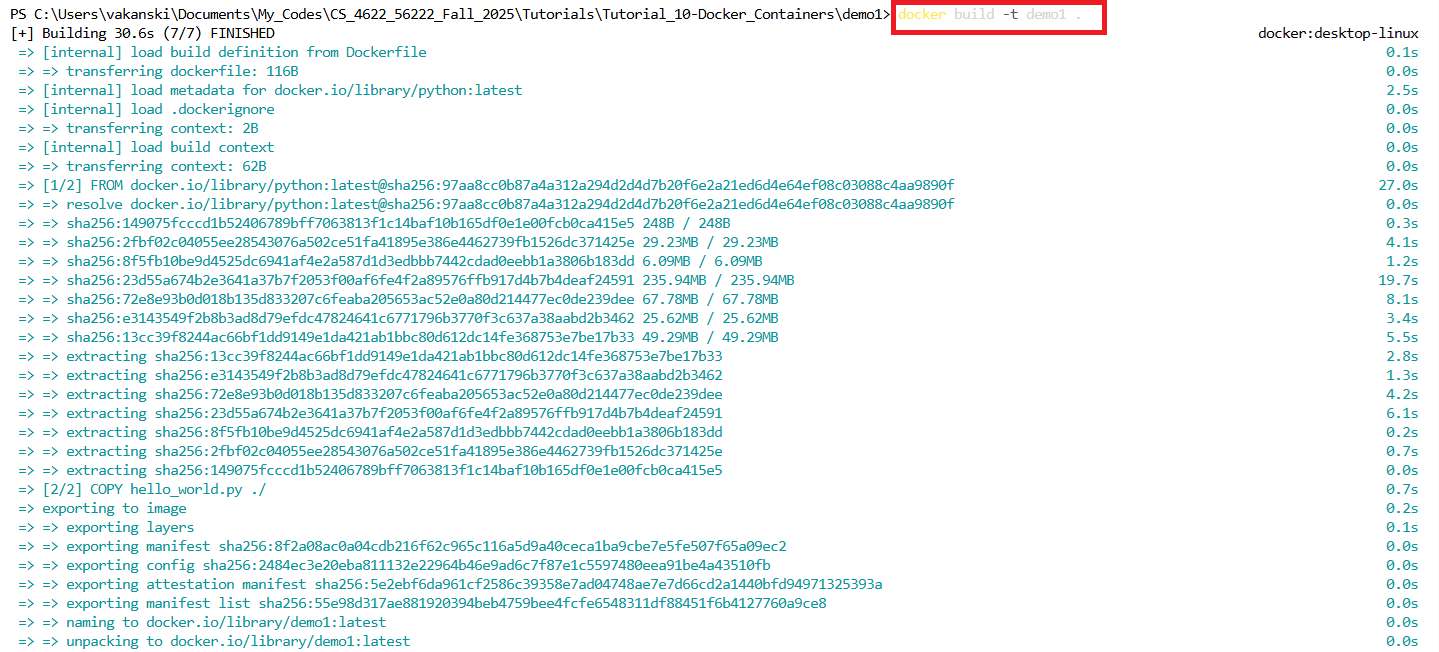
To build a Docker image from the Dockerfile, we will use the following code.
docker build -t demo1 .
Docker code begins with the keyword docker. The command build specifies to build a Docker image. -t is used to set a tag to the image, and in this case we tag the image with the name demo1. The dot . at the end of the line specifies to build the image by using the Dockerfile that is located in the current directory where hello_world.py script is located.
The Docker image that we just built represents a collection of files that are required for an operational environment. Each of the files that make up a Docker image is referred to as a layer. The images can contain multiple application codes and dependencies, i.e., they can have multiple layers.
In general, it is possible to build a Docker image by typing Docker commands interactively in the command line, and creating a Dockerfile is not required. However, Dockerfiles provide convenience and a documented record of the steps taken to assemble an image.
Step 4: Run the Docker Container¶
To run the image, we just use the run command, followed by the image tag demo1. This will execute the hello-world.py script in the container, which will display Hello World! in the terminal.
docker run demo1

In summary, we created a container that is independent of our local machine and that has an implementation of Python, and we displayed a message in that container.
Conclusion
The figure below shows the basic steps in Docker. We begin with a Dockerfile that contains the required commands to build a custom Docker image for our application. The Docker image is a custom environment, that contains the required code, libraries, and dependencies for the application. Docker containers are run using the Docker image. Within a container, the image comprises all the required files to run the application. By using containers, applications are isolated from other processes, preventing other processes from affecting the current application.

Docker containers have an analogy with cargo containers used for shipping products. Once we place our product (code and dependencies) in the container, we can ship it by boat or train (laptop or cloud), and when it gets to its destination, it continues to function (run) just as before the shipment was made.
And one more note is that Docker has an official Hello World image, which can be run directly from the terminal, and it is typically used by users when they install Docker for the first time to verify that it works properly. The following figure displays the output of the Hello World image.

Scikit-learn Models in Docker¶
In this section, we will learn how to create a container for running a scikit-learn model.
To demonstrate the concept, we will use the California Housing Dataset that is available in scikit-learn, and that we also used in Lecture 14 when we studied regression with ANNs. The dataset contains 20,640 records about housing prices in California, and it includes 9 features related to the number of rooms, population, latitude, longitude, and similar information. The target column is the median value of the house. This is a regression problem, where the goal is for a given set of input features to predict the housing price.
For this task, we will create a new folder, containing a Dockerfile to build the Docker image, train.py script for loading the dataset, training the model, and saving the model parameters, and inference.py script for loading the trained model and predicting on test instances.
Demo2-sklearn
├── Dockerfile
├── train.py
├── inference.py
Step 1: Create Train.py script¶
The code in train.py script is shown below (note that if you run the cell in this Jupyter notebook, it will give errors, because the code is intended to be executed as a script).
This script is easy to understand. We import the necessary libraries, load the data, fit a Gradient Boosting Model, and save the model. From the imported joblib package we used the dump method to serialize the model parameters and save them at the MODEL_PATH location. Also note that the train.py script defines the paths to the directory MODEL_DIR and saved model MODEL_FILE. This will allow to pass the path to Docker at build time, and embed these locations into the Docker
image. The MODEL_DIR and MODEL_FILE environmental variables are defined in the Dockerfile in the next section. Then, when the container is run, the script will read the locations of the files from the image, and use the saved model to predict on new data during inference.
[ ]:
# Import libraries
import numpy as np
from sklearn import ensemble
from sklearn.datasets import fetch_california_housing
from sklearn.model_selection import train_test_split
import os
from joblib import dump
# Load and split data
housing = fetch_california_housing(as_frame=True).frame
X = housing.drop('MedHouseVal', axis=1)
y = housing['MedHouseVal']
X_train, X_test, y_train, y_test = train_test_split(X, y, random_state=13, test_size=0.2)
# Fit regression model
model = ensemble.GradientBoostingRegressor()
model.fit(X_train, y_train)
# Directory paths
MODEL_DIR = os.environ["MODEL_DIR"]
MODEL_FILE = os.environ["MODEL_FILE"]
MODEL_PATH = os.path.join(MODEL_DIR, MODEL_FILE)
# Save the model
dump(model, MODEL_PATH)
Step 2 Create Inference.py script¶
The script inference.py is very similar to train.py, except that the trained model is loaded, and in the last few lines of code, the loaded model is used to predict the price for the first 10 instances from the test dataset. The output includes both the predicted prices and the ground-truth prices from y_test.
[ ]:
# Import libraries
import numpy as np
from sklearn.datasets import fetch_california_housing
from sklearn.model_selection import train_test_split
import os
from joblib import load
# Load and split data
housing = fetch_california_housing(as_frame=True).frame
X = housing.drop('MedHouseVal', axis=1)
y = housing['MedHouseVal']
X_train, X_test, y_train, y_test = train_test_split(X, y, random_state=13, test_size=0.2)
# Directory paths
MODEL_DIR = os.environ["MODEL_DIR"]
MODEL_FILE = os.environ["MODEL_FILE"]
MODEL_PATH = os.path.join(MODEL_DIR, MODEL_FILE)
# Load model
model = load(MODEL_PATH)
# Run inference
y_pred = model.predict(X_test[:10])
print("Predicted price by the model:", np.around(y_pred,1))
print("Ground-truth price:", np.array(y_test[:10]))
Step 3: Create Dockerfile¶
The Dockerfile for this project is provided below, and contains the following parts:
FROM jupyter/scipy-notebookuses a pre-built imagejupyter/scipy-notebookas a base image. The image contains apythoninstallation,scipy, and other libraries to facilitate working withJupyter. This image will be downloaded from Docker Hub.The next lines are used to first create a new directory called
modelwhere the trained model will be saved. Afterward, 2 environment variables are defined forMODEL_DIRandMODEL_FILEthat will reference the newly created directory and the name of the saved model. The directory/home/jovyan/was set in the imported base imagejupyter/scipy-notebook.The
COPYcommands are used to copy thetrain.pyandinference.pyscripts from our local machine to the working directory of the image.RUN python train.pywill execute the script to train and save the model. This will ensure that the model is saved at a specific location , and it is ready to predict on new data when the image is run. An advantage is that if the model training fails, it will happen when we build the image rather than at run time, which allows to debug the issue.CMD [ "python", "./inference.py"]will execute theinference.pyscript when we run the container from the image.
[ ]:
FROM jupyter/scipy-notebook
RUN mkdir model
ENV MODEL_DIR=/home/jovyan/model
ENV MODEL_FILE=model.joblib
COPY train.py ./train.py
COPY inference.py ./inference.py
RUN python train.py
CMD [ "python", "./inference.py"]
Dockerfile Commands¶
Common commands that are used in Dockerfiles are shown in the next table.
Command |
Purpose |
|---|---|
FROM |
To specify the base image from which the container is built. |
WORKDIR |
To set the working directory. |
RUN |
To install any libraries and packages or perform setup steps druing image build. |
COPY |
To copy files or directories from the local build context into the image. |
ADD |
To add remote URLs and unpack compressed files. |
ENTRYPOINT |
To specify commands to be executed when the container starts. |
CMD |
Commands the container executes. |
EXPOSE |
To define the port to access the container application. |
LABEL |
To add metadata to the image, such as author, version, or description. |
Step 4: Build the Docker Image¶
Next, we will build a Docker image from the Dockerfile, similarly to the previous example. Often, tags in the form image_name:tag_name are used, as in this case, where we assigned the image name demo2-sklearn and we assigned the tag name 0.1. The tag name allows to apply versioning to Docker images, where, for instance, we can assign tag name 0.2 to the next version of image, or 1.0 if significant updates have been applied. If the tag name is omitted, Docker will pull the
most recent image version, which is identified by the tag latest.
docker build -t demo2-sklearn:0.1 .
To list the Docker images that we have built, we can use, well, docker images shown in the figure. Note that the image demo1 has the tag name latest, and the image demo2-sklearn has the tag name 0.1.

Now that we have an image that contains a saved trained model, next, we will run a container to make predictions using the model.
Step 5: Run the Docker Image¶
We run the image by using docker run and the name of the image. This will load the saved model, make predictions, and display the predicted house prices for the first 10 records in the test dataset. For comparison, the target prices for the first 10 records are also displayed. In a real-world case, the model will make predictions on new data samples (e.g., the price for house information that may be inputted by a realtor).
docker run demo2-sklearn:0.1

Note as well that we can launch multiple containers from one Docker image, with the containers maintaining their own individual state although sharing the same image. The changes to each individual container are stored in a container layer.
Docker Desktop¶
Docker Desktop for Windows uses the Windows Subsystem for Linux (WSL2) to run Linux-based containers natively. It provides lists of all created images, containers, and other related information. For instance, in the Containers section, we can see the two containers that we run demo1 and demo2-sklearn with tag names latest and 0.1, respectively.

Docker Registries and Repositories¶
Container repositories are the physical locations where Docker images are stored. Each repository contains different versions of each image, where each image is referenced by a different tag. For example, on Docker Hub, mysql is a repository that contains different versions of the Docker image for MySQL.
Container registry is a set of repositories. The main types of container registries are:
Docker Hub: it is the official public container registry maintained by Docker, which hosts over 100,000 container images created by software vendors, open-source projects, and Docker’s community of users.
Third-party registry services: are managed registries that allow users to store and share their Docker images. Examples of third-party registries include Azure Container Registry, Google Container Registry, Amazon ECR, Red Hat Quay, and JFrog Container Registry.
Self-hosted registries: are managed by organizations that prefer to host container images on their own on-premises infrastructure, typically due to security, compliance concerns, or lower latency requirements. Running self-hosted registries requires to deploy a registry server.
Pull and Push images on Docker Hub¶
As we mentioned, Docker Hub allows users to host and manage their own images, where Docker images can be easily shared between collaborators, allowing every collaborator to use reproducible environment.
To push built images to the Docker Hub registry, users will need to first log in to Docker Hub and then use the code to push the image.
docker login --username=your_username --password=your_password
docker push username/image:tag
Also, pulling images by other developers from Docker Hub is very easy, and allows to use other images with little or no modification.
docker pull username/image:tag
Benefits of Docker¶
Code and dependencies can be packaged together into portable containers that can be run on a variety of different hosts, regardless of the hardware or operating system.
Provides versioning of build environments, where image versions can be tracked and rolled back.
Allow to replicate the working environment that is needed to train and deploy machine learning model on any system, and removes the reproducibility challenges.
Trained machine learning models can be easily wrapped into an API in a container, and deployed to remote servers.
References¶
Full Stack Deep Learning course, Lecture 11: Deployment & Monitoring, available at https://fullstackdeeplearning.com/spring2021/lecture-11/.
ML in Production, Docker for Machine Learning, by Luigi Patruno, available at: https://mlinproduction.com/docker-for-ml-part-1/.
A Beginner’s Guide to Understanding and Building Docker Images, available at: https://jfrog.com/knowledge-base/a-beginners-guide-to-understanding-and-building-docker-images/.
Machine Learning with Docker, Demonstrations about Using Docker for Machine Learning, available at: https://github.com/BINPIPE/docker-for-ml.
BACK TO TOP